No doubt, building large-scale retrieval systems will help many people around the world on a daily basis, but such a system also have many challenges like handling a lot of data, returning results as quickly as possible etc. Keeping pros in mind, Google started working on the problem since 1997. The very first project of Google in this field was named "Circa".

What is Large-Scale Retrieval System?
Retrieval Systems are the systems that span a lot of area of Computer Science like Computer Architecture, Distributed Systems, Machine Learning, Information Retrieval etc. These systems almost work in every field related to Computer Science. Now, when there is a lot of data from where one has to perform a search, then there comes the concept of Large-ScaleRetrieval Systems. The main thing one can keep in mind while creating a module of Large-Scale Retrieval System is the time consumed while retrieving the relevant documents to the query.
The following parameters affect the overall performance:

What is Large-Scale Retrieval System?
Retrieval Systems are the systems that span a lot of area of Computer Science like Computer Architecture, Distributed Systems, Machine Learning, Information Retrieval etc. These systems almost work in every field related to Computer Science. Now, when there is a lot of data from where one has to perform a search, then there comes the concept of Large-ScaleRetrieval Systems. The main thing one can keep in mind while creating a module of Large-Scale Retrieval System is the time consumed while retrieving the relevant documents to the query.
The following parameters affect the overall performance:
- Queries
- Index Update rate
- Number of documents indexed
- Query latency
- The complexity of retrieval algorithms
- Information stored about each event.
The following table shows the growth in the dimensions of the retrieval system. By the time of 10 years almost everything has increased and along with that more powerful and fast machines were installed in that period.

The main component of Large-Scale Retrieval System is Index Construction. Index Construction is the process by which the documents are stored in the database. Here storing means that the index provided to the records stored in the databases. Two ways can do the process:
- By using Docs:

- By using words:
So, based on the above two techniques the fundamental principle that Google used to design Circa in 1999 is splitting the data into two parts Index serves that have a complexity of O(K*N) and Doc Servers that have a complexity of O(K).

They have used Cache servers too that caches both index results and doc snippets. The hitting time on this server is 30-60 %.The main benefit of this system is the performance. It has reduced the query latency.
But there is a drawback of the system and that arris when the cache is flushed.
So, keeping that in mind, Google and other big companies have to come up with some algorithm whose memory can increase dynamically depending on the increase in the number of documents for the system. That is the system must handle the dynamic increase in the number of documents and index updates too.
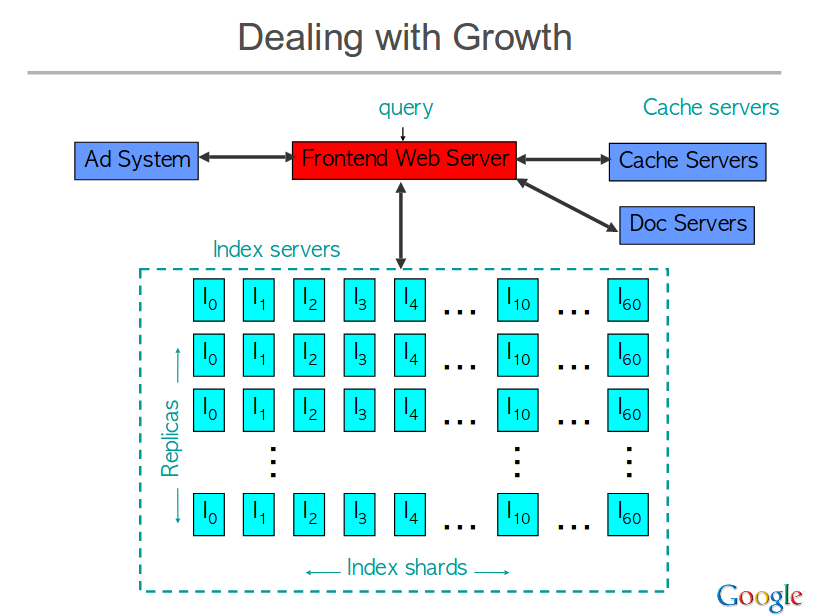
After Circa, Google works on a system that uses the techniques like In-Memory Indexing, Large Scale Computing, more advances serving design etc.
Refrences:
- https://research.google.com/people/jeff/WSDM2009-keynote.html
- https://static.googleusercontent.com/media/research.google.com/en//people/jeff/WSDM09-keynote.pdf
- https://witness.theguardian.com/assignment/532026eae4b09b68d7845879/874495
- http://videolectures.net/wsdm09_dean_cblirs/
I really enjoy the blog.Much thanks again. Really Great. salesforce Online Course
ReplyDelete